
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 디버그모드
- Machine Learning
- FLASK
- 지능형
- MySQL
- Video
- Deep Learning
- tracking
- 데이터
- 안드로이드
- php
- Android
- 머신러닝
- Linux
- 가상환경
- Object Detection
- Python
- Raspberry
- detection
- IMAGE
- 정리
- 영상분석
- C언어
- sw
- keras
- 라즈베리파이
- tensorflow
- 고급C
- 서버
- RapidCheck
- Today
- Total
목록Regression (3)
건프의 소소한 개발이야기
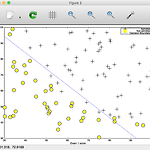 [ML - Matlab/Octave] Logistic Regression
[ML - Matlab/Octave] Logistic Regression
안녕하세요, 건프입니다. 이번엔 ML 에서 Linear Regression 을 넘어서 Logistic Regression 에 대해서 익혀봅니다. Linear 의 기법으로 접근하는 것은, 대상을 연속하는 선의 관점으로 바라보는 것이고,Logistic 은 문자 그대로, 1 또는 0, 불 대수 논리로 접근하는 것을 의미합니다. 대표적인 사용법이 시험에 대한 "합격/불합격" 을 판단하는 함수를 만들 수 있겠네요. 1. 데이터를 로드하고, 데이터를 Feature 와 Result 로 구분하는 작업이 필요합니다.첫번째 열은 시험1 의 점수두번째 열은 시험2의 점수세번째 열은 합격과 불합격을 각각 1, 0 으로 나눠놓은 데이터 입니다. 2. 데이터를 나눴으니, 그래프를 그려봅시다.그래프를 그리기 위해서는, y 데이터가..
 [ML - Matlab/Octave] Linear Regression with Multiple Variables
[ML - Matlab/Octave] Linear Regression with Multiple Variables
안녕하세요, 건프입니다. 앞에서는 수많은 학습데이터들을 이용해서 패턴을 분석하는 예측함수를 구하고,그 예측함수를 이용해서, 현실값과 가장 차이가 적게나는 계수값(세타값들)을 구해서다음 들어올 데이터를 이용해 현실값과 가장 근접한 예측값을 뽑아내는 것을 했습니다.(사실 이것이 Data Based Machine Learning 기법의 전부인 듯한..) 다만 한가지 맹점은, 그 학습하는 데이터의 특징(Feature)가 단 하나여야 했다는 것이죠.데이터의 특징이 하나라는 의미는 다음과 같아요.ex> 집값을 결정하는 요인(feature)는 '집의 크기' 뿐이다.이럴 때, 집의 크기는 요인(feature)이고, 값 결정의 요인이 단 하나이므로 생각보다 간단하게 구해낼 수 있습니다. 하지만 이세상의 대부분의 경우는 ..
 [ML - Matlab/Octave] Linear Regression with Single Variable
[ML - Matlab/Octave] Linear Regression with Single Variable
안녕하세요, 건프입니다. 이번엔 데이터처리를 간단하게 도와주는 Octave 라는 프로그램으로 Linear 한 예측함수와 그래프를 만드는 것을 해보려고 합니다. 1. 우선 데이터를 메모리 상으로 로드해야합니다. Octave에서는 공백기준으로 나누어져있는 데이터를 행렬데이터로 다음과 같이 쉽게 로드할 수 있습니다. 위 데이터에서 첫번째 열(column) 은 데이터 값(지금은 Single variable 이므로 고려해야할 데이터값이 하나입니다) 이고, 두번째 열은 실제 도출된 결과값 에 대한 정보입니다. 2, 우리는 이 데이터를 X(input data) 와 y(real output data) 로 나눠야 합니다.나누는 방법은 다음과 같습니다. 첫번째 인자의 : 는 모든 행의 값을 모두 가져와달라는 의미이고두번째..